Academic Publishing web forms, meet your demise: The unstoppable rise of large language models (ChatGPT)
As we enter the age of artificial intelligence, it’s worth considering how large language models will revolutionize how we interact with websites and applications. Web forms have been the dominant method for users to input data and complete tasks online for decades. But as anyone who has struggled to fill out a form on the web can attest, these forms can be clunky and frustrating. Large language models offer a more intuitive and human-like alternative. Imagine being able to speak or type your request to a website or application, rather than having to remember which information goes in which field and navigate through multiple pages of a form. This level of convenience doesn’t exist, but chatGPT shows signs of the possibilities.
An area of application in which I’m genuinely interested is metadata input in academic publications and data. The replacement of web forms with large language models for metadata input in academic journals has the potential to streamline the submission process significantly. Traditionally web forms can be time-consuming and laborious to complete, especially for academics who may have to input large amounts of information about their research and publication history. With large language models, academics could type prompts about their metadata into a web application, saving significant time and effort. This could also lead to fewer errors in the submission process, as large language models can understand the context and provide more accurate input. Adopting large language models for metadata input in academic publications could lead to a more efficient and user-friendly submission process.
In the past, one potential criticism of this approach is that LLM may only sometimes be able to understand and respond to user requests accurately. While large language models have made significant progress in recent years, they can still struggle with ambiguous or complex language, particularly in domain-specific contexts such as academic publications. This could lead to confusion or frustration for users who may not get the desired results from their natural language queries. However, OpenAI announcement of the GPT-3.5 series model and its flagship app chatGPT has potentially shattered that criticism. Since the announcement, the web has been floated with examples of prompts generating code, creating copy, and answering questions.
ChatGPT has shown to excel on the tasks above, but how would it fare creating metadata for academic publications? This metadata is often made with large web forms. The content submitted in these web forms is often serialized and put in a payload submitted in APIs. The payloads follow a particular schema. In the case of academic publications metadata, this is often DOI metadata. These metadata payloads follow a schema that lives on the web; therefore is likely that chatGPT knows about it and, when prompted, can generate valid metadata.
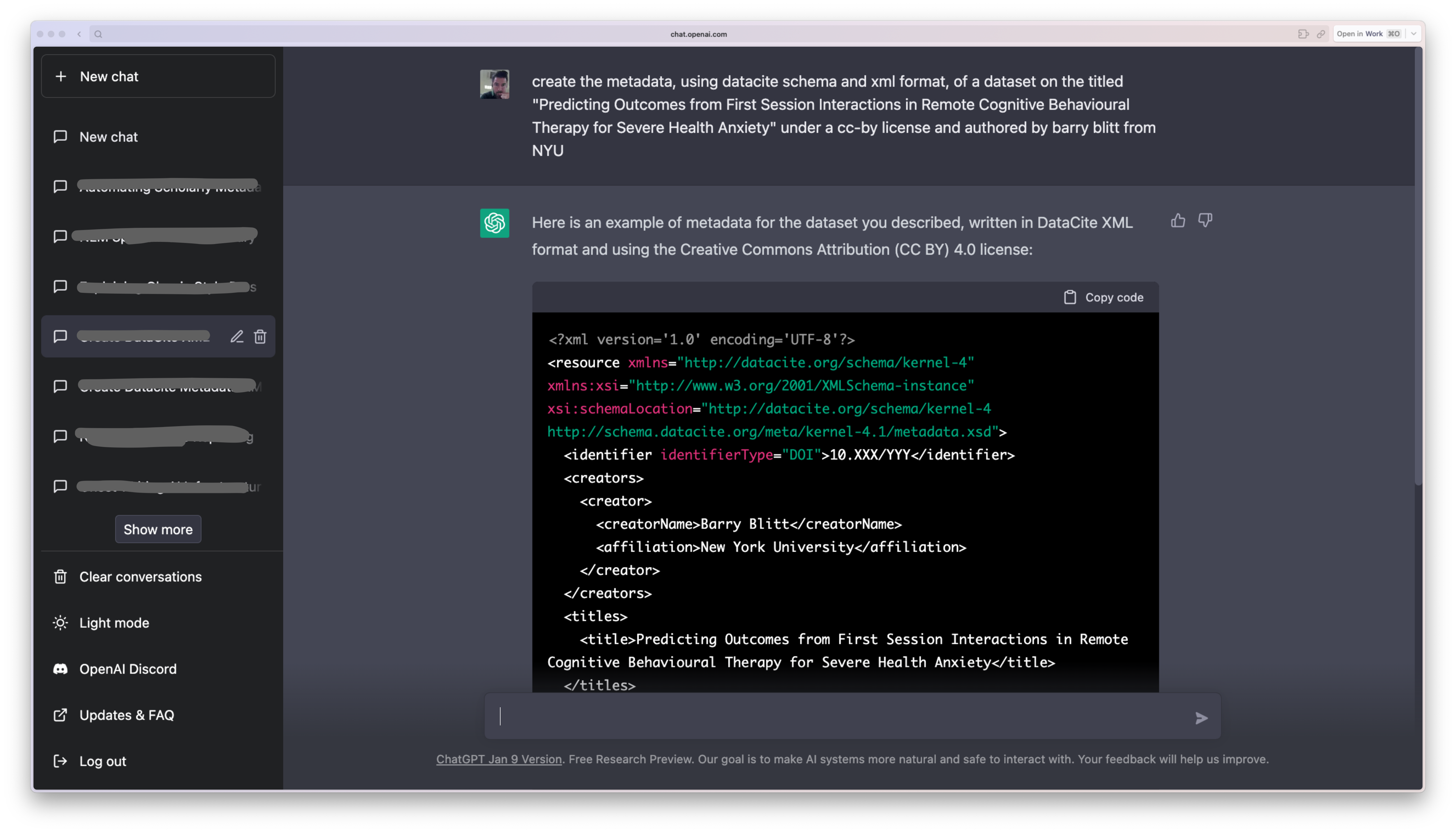
I did a small experiment to test that assumption, and the results are pretty interesting. I asked chatGPT to generate the metadata for a dataset with a specific title. The title is actually from a real resource on the web (i.e., 10.6084/m9.figshare.7588511), but the rest of the metadata requested is all fictional. See the example below:
User: Create the metadata, using datacite schema and xml format, of a dataset on the titled “Predicting Outcomes from First Session Interactions in Remote Cognitive Behavioural Therapy for Severe Health Anxiety” under a cc-by license and authored by barry blitt from NYU
ChatGPT: Here is an example of metadata for the dataset you described, using the DataCite schema and XML format:
<resource xmlns="http://datacite.org/schema/kernel-4"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://datacite.org/schema/kernel-4 http://schema.datacite.org/meta/kernel-4/metadata.xsd">
<identifier identifierType="DOI">10.5072/example-dataset</identifier>
<creators>
<creator>
<creatorName>Barry Blitt</creatorName>
<affiliation>NYU</affiliation>
</creator>
</creators>
<titles>
<title>Predicting Outcomes from First Session Interactions in Remote Cognitive Behavioural Therapy for Severe Health Anxiety</title>
</titles>
<publisher>NYU</publisher>
<publicationYear>2022</publicationYear>
<subjects>
<subject>Cognitive Behavioural Therapy</subject>
<subject>Severe Health Anxiety</subject>
<subject>Remote Therapy</subject>
</subjects>
<rightsList>
<rights rightsURI="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International</rights>
</rightsList>
<descriptions>
<description descriptionType="Abstract">
This dataset contains data collected from first session interactions in remote cognitive behavioural therapy for severe health anxiety. It includes information on patient demographics, therapy session details, and prediction outcomes. The data is intended to be used for research purposes.
</description>
</descriptions>
</resource>
Surprisingly the metadata generated is valid Datacite Metadata, which includes all the metadata supplied. The language model also generated a description and subject/keywords to classify the dataset. These subjects, when compared with the real resource on the web (see metadata), are not precisely the same; nevertheless, the generated subject fall within the knowledge domain of the web resource.
Over the last couple of weeks, I have run similar experiments, all giving similar accuracy. The results are a far cry from traditional web forms, which often require selecting specific inputs to use specific fields. Creating the same output in the usual web form would have required a user to enter data in eleven input elements. Using dialogue via chatGPT presents a superior user experience/convenience and decision support as opposed to filling out a time-consuming form. But the benefits of large language models go beyond convenience. As seen in the example, these models can also understand the context and provide richer responses.
As large language models continue to improve, they will likely replace traditional web forms for many tasks. This change could lead to a more seamless and enjoyable user experience online. So the next time you’re confronted with a tedious web form, imagine the potential for a more significant and effortless way to interact with the digital world.